| Archive: Issue 7 - Spring 2001 |
||
The
Coming Job Glut: Expanding Work in The High-Tech Sector
(page 2 of 3)
By Ivan Handler Infoglut The retrieval of information thus depends upon the classification of data. This is where things start becoming even more problematic. Information is usually classified based on the current classification models used when the data is entered. In many cases these classifications are not useful when the information is opened up to larger circles of requestors. What happens then? Either a large project must be undertaken to reclassify information so it is useful to the larger circle. Or workers must be retrained to do the reclassification. Or special expensive software may be designed or purchased that purports to do this automatically. Or, most likely, a combination of all three. Now let's say the information is successfully reclassified, and the corporation is even more efficient. This means that even more information is being produced at an even faster rate. As competitors catch up, more pressure is put on the corporation to integrate more information into its systems and to make it available to even larger audiences. This causes another problem with reclassification, which leads to even faster information production, and so on. Sheer volumes of data can also force the need to refine classification data. As more data is entered into a system, more and more data falls under the same classes. This may not be a problem for people who know unique combinations of elements that can be used to find what they need. But it is a problem for the majority who do not have that knowledge. In any event reclassification becomes necessary and users must be trained in the new system. Or the corporation must rely on automated classification software that can processes millions of data elements, but cannot understand human language. In some circumstances, this means critical data can be lost unless someone can correctly deduce the right combination of factors to use in a query. Anyone who has used an internet search engine to look for obscure data has experienced this first hand. With the internet becoming not only the common means of exchanging information, but the common repository for information, this cycle builds up even faster since any time anything is added to a repository, some portion of it will be opened up to the internet. There are two responses to this situation: 1) build new search/classification software to handle the increasing load and 2) build new information specialty businesses or business units that can provide information very quickly in a very narrow range of topics. The latter expansion is referred to as both horizontal and vertical growth. Horizontal growth refers to expansion into new areas and vertical growth implies deeper expansion into existing areas. Of course these solutions must be short lived. Since no matter how efficient the search software is, when enough new information is added to a repository, searches that produced short lists of possible resources start to produce lists that get larger and larger until the searches become useless and must be refined. The same goes for information specialists. Sooner or later what started as a small niche will be seen as overly general and unmanageable so that newer smaller niches will need to be created. Since the whole dynamic of the information revolution is to produce more and more information with increasing acceleration, these solutions will become obsolete faster and faster. While lots of salespeople who sell the latest search/classification software based on the latest computational linguistic techniques will claim that they will have this problem solved within a few short software generations. This does not seem very credible to me. The whole history of software is riddled with these overly optimistic claims that never come true. In part this is because it is easy to make large strides in software when you enter new territory. This breeds a simplistic optimism that all problems will turn out to be this simple, so that a linear extrapolation of the progress that has been made yields fantastic claims for the near future. As in all technical fields, the first few remarkable bursts of activity usually yield to long years of slow and uncertain progress. Infoglut causes Jobglut The effect this dynamic has on employment is what we want to look at now. In this case it should be obvious that as the information management problem grows exponentially, the need for high-tech workers grows right along with it.
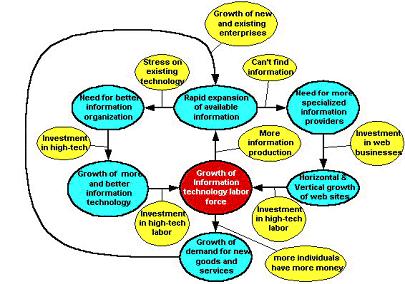
The more high-tech workers that are found, the more information that is produced giving rise for the need for even more high-tech workers to help manage the resulting information explosion. As automation erodes the need for low skill labor, it is dramatically increasing the need for high-tech labor. Finally, the larger the size of the high-tech labor force, the more money they have to spend on goods and services. In turn this stimulates the economy, which translates into more information expansion, which re-enforces the rapid expansion of the high-tech labor sector. The above arguments can be summarized in the following diagram: Blue and red bubbles represent conditions, arrows are the responses, and yellow bubbles label the responses. The arrows imply the response contributes to the condition its arrowhead touches. The problem is that the industrial culture we are leaving has built up a political structure that functions as a barrier against bringing those at the bottom who need family sustaining jobs to the corporations who need more high paid workers to manage the information crisis they are creating. Information and Technology Cycles So how fast is the automation/information-production cycle? Having no direct statistics, the best indicator that I am aware of is in the growth of technology. There are several indicators that are consistent with the above views. Moore’s law invented by Joe Moore states that roughly every 18 months the processing power of computer cpu’s (central processing units) will double. While there is some suspicion that this will eventually end, it is not clear when. It has held true now for at least 20 years. Interestingly enough, according to Jon William Toigo in the May 2000 issue of Scientific American: “Many corporations find that the volume of data generated by their computers doubles every year. Gargantuan databases containing more than a terabyte—that is, one trillion bytes—are becoming the norm …(4)” This means information appears to be growing in some sectors faster than a major element of information processing technology, processor power. The concrete ways Moore’s law contributes to information production are:
“Cyberimperialism”. In order to create chips with higher and higher component densities (this is what makes Moore’s law work), newer, more sophisticated and much more expensive factories must be built. It now costs over $1 billion to build a state of the art chip factory. In order to make a profit on the chips before the factory becomes obsolete, more chips must be produced and sold than previous generations. The way to make sure that happens is to create new mass marketable devices in ever expanding commercial and consumer markets. So we now have not only PalmPilots, we have all kinds of computer game devices, computerized dolls, soon computerized kitchen devices such as internet enabled refrigerators and microwave ovens. (No joke. They maintain automated lists of groceries and can automatically reorder from your net-based grocer when supplies are low.) The only way to preserve profits is to expand markets into newer untouched areas of human culture. This expansion also adds to the information explosion. Information architectures are also changing. This is also driven by the need to handle more information faster. There are really four main generations of computer architecture(5):
While the effect of the spread of new architectures is hard to quantify, it does indicate a new faster information growth trend is now underway. New Employment Niches So far we have been talking primarily about employment that directly serves corporate needs. The growth of the Internet is also giving rise to potential niches serving consumers who use the net, the majority of whom are high-tech workers because of their familiarity with the net as well as the amount of money they have to spend. Consumers, whether they are working for corporations in a particular capacity or just out for themselves, are finding it increasingly difficult to find what they want on the internet. Portal sites such as Yahoo, Excite, Netscape, AOL, MSN and others are one response. These sites are attempting to become the entrance points for all users on the web, providing them with access to both search engines and large indices that help users find what they are after. Shopping portals such as My Simon have also arisen. These sites will allow a consumer to find goods and services offered by a generally large set of online businesses and to comparison shop right then and there. The affect this is having on prices and what the outcomes will be is another very interesting phenomena to watch. On the other hand, none of the search engines or portal sites can account for any more than about 20% of all of the web pages available. It is still quite common to find “dead urls” (web addresses that no longer exist) when using these sites to find information. As a result more specialized sites are evolving such as Slashdot for the heavy techie or Arts and Letters Daily for those interested in literature, philosophy and opinion. Just as Usenet has provided thousands of sites to host specific discussions, “electronic communities” are forming everywhere with all kinds of specific focuses. In fact the latest dot.com consultants are advising all businesses to transform themselves into electronic communities where consumers interact with each other as well as the corporations workforce to not only buy and sell products, but to actually design and build products. Another important development is arising and that is for “micro payments”. This is a combination of technology for ecure buying and selling and arrangements with the financial industry to allow for sites to make money off small payments that may be as low as a tenth of a penny. When this technology becomes ubiquitous on the net, we will probably see a shift in many sites from “free” information (with lots of advertising) to sites with little or no advertising but small fees charged for each access. When you realize that some estimates indicate that there will be over a billion users on the net by the end of 2005 or sooner, you can see the reason for micropayments. More >>
|
||
| |
||
WELCOME!
You are visitor number |
Designed
by ByteSized Productions © 2003-2006